Concepts
What is a Columnstore Table?
Columnar storage improves analytical queries by storing data vertically, enabling compression and efficient column-specific retrieval with vectorized execution.
pg_mooncake architecture:
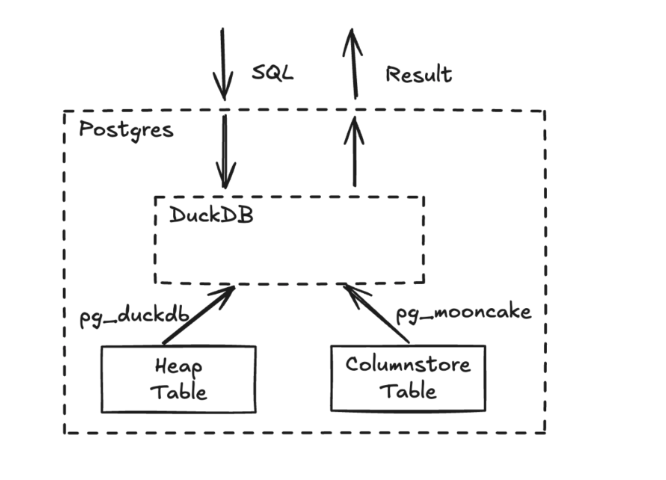
Queries on columnstore tables are executed by DuckDB. Metadata of columnstore tables are stored in Postgres, and data is stored in object store.
What is Iceberg / Delta Lake?
Iceberg and Delta Lake are becoming the agreed-upon storage format for analytic workloads.
Technically, they are a metadata layer over Parquet files, giving full table semantics.
What does pg_mooncake mean by Iceberg/Delta Columnstore table?
In Postgres, a columnstore table is just like a regular heap table.
Outside of Postgres, you can query the same table directly with Snowflake, Trino, DuckDB, Presto, Spark, Polars.
If data is stored in S3, how do we get sub second performance?
Cache on writes. Cache on reads will come in v0.2.
For best peformance, co-locate your object store bucket and Postgres instance.